posted
Nah, just my Reduxes. Wanna setup a dedicated lab though. Hoping the Big Two who have that experience will school me how.
Tukuler Member # 19944
posted
The main reason I like ADMIXTURE itself, compared to the rest of that package, is it's straight forward.
It seems anyone of no 'science' background at all can look at an ADMIXTURE graph and see how regions or populations are related or not, by real biological ancestry.
It's based on a broad swathe of DNA, far more than 2 bi-parentals or the up to 21 STaRs of autosomes.
You can interpret a worldwide sample set by noting K2 run as the Continental and Out of Africa divisions (roughly) K3 run as the old tri-racial model to some extent K5 run as the updated 5 race model K7 run as the 7 continental regions
Higher K runs then show regional or 'ethno-linguistic' substructure. So do non-global runs regardless of K. Here's how REDUXing comes into play. By sorting colors to show exemplars, majorities, and lastly pluralities, it looks like the time hoary meeting and mingling of peoples pops right out there before your very eyes and I believe my lieing eyes I do.
ADMIXTURE answers questions and its answers call new questions in turn begging for a run. Questions, like the Dinka/Mediterranean African one that just came up, can be partially answered by one glance at an ADMIXTURE. Somebody's got to pick out relevant samples and make the runs (ok more time consuming than PCs, or F/D Stats, etc).
PC is compartmentalized 1 2 3 4 decreasing percentages of exactly who knows what components? F and D Stats? Who remembers how to interpret them without continual familiarity? Then, what about the order the runner places which population in? Results will vary but trained users of course know each place/position to correctly place the test populations.
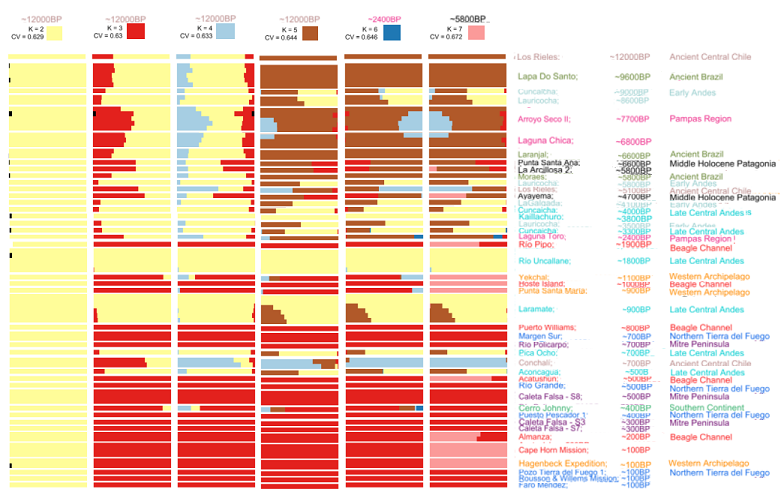
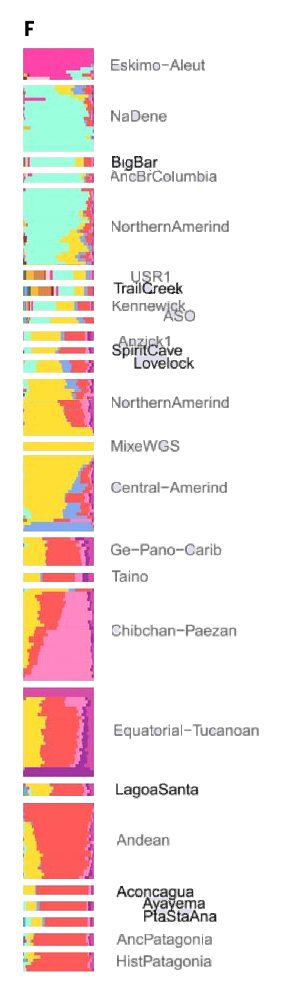
I've been on an ADMIXTURE trail of Americans. Those we call Indians aren't the only Americans nor do Indians claim shared origins with those others. My interest is Indians ancestries and percentages in various peoples.
For me that helps see American ancestries start/spread throughout both continents and Meso-America. Here, have a sneak peek at my Nakatsuka 2020's SF2 aDNA only redux. Unlike any before, this one is sorted strictly by time. Three major southern continent lineages go back to the early Holocene 12,000 ears ago, and are all over that continent.
OK for real? Testing for African ancestries that many assert exist. One big hitch. Reports on aDNA aren't including Africans though one study reports on TSI and IBS. Not knocking that. IBS shows insignificant (≤3%) Indian admixture. This supports history saying Indios in miniscule numbers were sent to Spain since Colon's mission.
See? That's the kinda thing I want to find out about Indians and Africans. Not expecting any significant ancient levels but how much would one expect of a few merchants from a visiting continent leaving offspring in the visited continent?
So I'm hoping the Big Two will more or less make a User's Guide to Running ADMIXTURE for ESers (me).
Wait, Willerslev Labs S17 does show African ancestry in Americans or I'm colorblind!
Tukuler Member # 19944
posted
In 2019 Stro posted an African ADMIXTURE run, in my opinion, more accurate in identifying ancestries than any published pro. Years ago I put up a comparison between his and a pro. The details why Stro's is better are there if interested.
However, my interpretation of Stro's graphed data is my own. I do not pretend to say Stro came up with or even agrees to any of the following. I'm using it as I would any of the peer reviewed published ADMIXTURE charts found on ES.
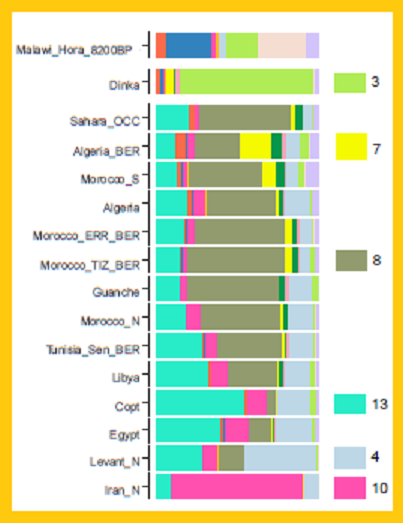
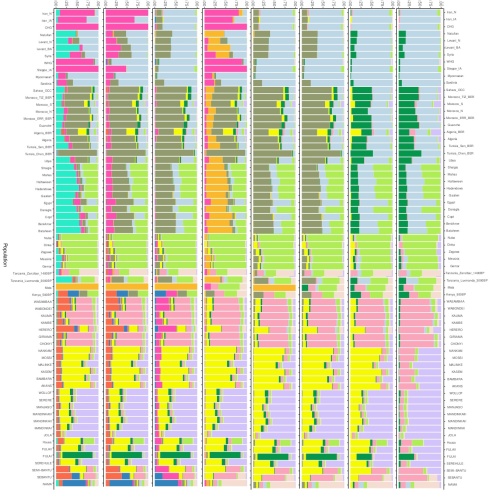
This redux looks at Dinka who are predominantly K3 (lime) with K7 (lemon) next most numerous though no where near K3's level. North African (and mideastern Neolithic) people share more with Sudanese like the Copt here with the ['north'] Sudan Bataheen exemplified ancestry.
'Lime' reps South Sudan populations. It's at least as old as Mt Hora Malawi, 8200 years. That's contemporaneous with the early to mid Holocene cusp, the much vaunted 'Green Sahara' era. Appearance is in all North Africans including Tunisia_Chen_ Ber at 'background', possibly absorbed(?), levels. Gaunche have way more of it than they do their barely detectable West Atlantic speaker ancestry. Did Lime move north from Malawi to disperse throughout Sahara founded populations just as it moved around southern Africa? The frequencies are relatively the same. (link)
'Lemon' is most common in Volta Rivers' peoples. Haven't noticed it in any ancient samples until, surprisingly, now. I'd doubt North Africans deriving Volta ancestry from Dinka based on this trustworthy evidence.
North Africa has no more South Sudan ancestry than other Africans from outside Sudan and South Sudan.
=-=-=-=
Now what could be controversial are the insignificant levels of South Sudan ancestry in Levant Neolithic and Voltaic ancestry in Iran Neolithic. The latter push that ancestry back into pre-history if valid (as additional runs, if concurring, would vet).
All I want is to be spoonfed taught by those who know on what simple equipment I need to store sample sets available for download and to run ADMIXTURE days on end if neccesary.
Tukuler Member # 19944
posted
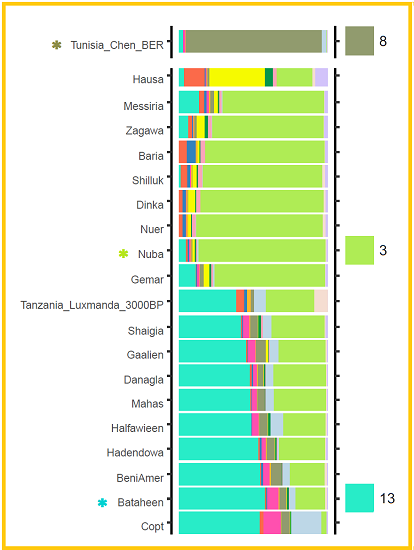
This redux focuses on Tunisia's Chenini Imazighen. They exemplify K8 (olive) North Africa ancestry. In the original 2019 run olive shows earliest in a Natufian slither but at a serious ~17% in the Neolithic Levant. (link)
Sudani peoples share early Holocene K3 (lime) ancestry in common. Nuba have the most. It's predominant in South Sudan. K13 (aqua), exemplified by Bataheen, is either the plurality or majority ancestry in the nation of Sudan peoples. Ancient K13 samples make a good Levantine showing. Nearly half in Natufian. Dropping to around a third in the Neolithic. Booming to over 50% by the Bronze Age.
Dinka have virtually no K8 (olive) North Africa exemplified ancestry. Ditto for others in South Sudan. It's past the significance mark, 3%, in Sudan including the south. If a North Africa influx is evinced by this ADMIXTURE graph it'd be in Sudan from Darfur corridor northeast to the Red Sea. Me? I don't see it.
Kinda foggy right now but the literature is full of people called Berber in the south of the North East Africa region but who they precisely were escapes me. Think I saw 'em in old Palmer.
Elmaestro Member # 22566
posted
I would help with a walkthrough, I've told others I didn't mind teaching them, but still haven't gotten around to it. It can take quite a bit of time and explanation. Maybe I can hold a zoom conference and walk some people through the basics all at once??
Also, Populations with high consanguinity can form their own cluster in Admixture (which is expected due to it's algorithm), So it's hard to make widespread inferences using their clustering. The Chenini component wouldn't be a useful indicator for components of populations who's movements/activity predate them(Chen).
Tukuler Member # 19944
posted
Thx 4 responding.
1st is the hardware.
What common non-exotic chines will do the job of 1. saving downloaded samples used and linked in texts 2. expediously running the ADMIXTURE pkg of programs?
I ain't niggardly so please no cheap stuff.
I'll need db and operative storage and data crunching power to spare. 125%-200% times required capacities. Nothing like legroom, stretching space, and x tra O2!
I intend to make at least 3 but preferably 10 runs to select the best CV for posting each K.
Plus the chine(s) MUST to be portable.
OK Santa that me wish list. Is it possible? Am I dreaming?
BTW been digging in your 2019 60 populations 13Ks run with all them prehistoric samples. That Roman guy in England who exemplifies the orange K. That K5 is sizable in a large variety of south Mediterranean, Sahra, Nile, and Red Sea Africans. What you think it is, where it come from, and how old is it?
Tukuler Member # 19944
posted
Yes of course. The higher the K the likelier a pop will get "it's own" color. I thought that what it was all about? I mean, that's what's so good about it to me.
It's not anything goes but no hard and fast interpretation rules are in effect either. Anything goes would be something like: increasing K# = more recent incipience. Since the early days, when some pro wrote a warning about over interpreting ADMIXTURE, each report(er) seems to opine at will.
Appreciate the heads up.
You might be misinterpreting me, i.e., 'missing my interpretation'.
Chenini are but one of 11 peoples with K8. K8 is a Sahra-MedAfrica ancestral component. Chenini merely have it at its highest frequency. Having some 90%, Chenini present a near perfect example of K8 ancestry, thus exemplary of K8 ancestry populations regardless of era.
Exemplify doesn't mean synonymous. Chenini =/= K8. Looking into your 2019 K4-13 PDF and reducing it to noticeable K8 bearing samples and including Ks 7&6 for the Fula-1 exemplified K6.
img is thumblink to full size -- Mayne, that's some wicked Mota runnin @ K=10
Since K=6, where K8 ancestry first 'congeals', seems all having them in meaningful proportion are indeed 'North African'. Remember, Fula I originate in North Africa around where Algeria, Libya, and Niger meet.
I'd agree Chenini aren't indicative of earlier populations. Great grandchildren don't define or shape their ancestors. The K8 ancestry greatly predates the Chenini's origin. K8 is the/an indicator of Sahra components in any population movement/activity well before Chenini and maybe even before Tamazight developed.
Does that make a smidgen of sense or you still think I'm whistlin' Dixie? Seriously. Though a stubborn ass, I am teachable. No knowitall claims.
quote:Originally posted by Elmaestro: Populations with high consanguinity can form their own cluster in Admixture (which is expected due to it's algorithm), So it's hard to make widespread inferences using their clustering.
The Chenini component wouldn't be a useful indicator for components of populations who's movements/activity predate them(Chen).
.
The non-K8 in peoples with at least a plurality of it can indicate particular K8 bearing groups' previous movements/activity pending known interactions whether direct as in living in proximity or indirect via immigrants, transhumance, merchants, adventurers, war, etc.
Chenini lack LemonLime. All other North Africans have some. Gaunche have Lime but no Lemon (ok for tequila or rum). Algeria Imazighen have more than twice the Lemon of any N Afrs. Lilac is in most North Africans yet missing in several.
Surely that's indicative of incoming movement and/or activity involving South Sudanese, Volta Rivers, and Sene-Gambian folk? Checking those peoples for K8, if any, reveals the reverse, i.e., outgoing Sahra-Med Africa interaction southeast, south, and southwest. Likewise for the weightier K13 aqua Sudanese and K4 grey Anatoli ancestries all Sahra-Mediterranean Africans share.
or
Am I a Fool walking off the cliff heedless to warning?
posted
What you're saying makes sense, but it doesn't really incorporate the fact I was trying to point out. if over 90% of a populations ancestry belongs to a single cluster, essentially they're assumed ancestors or highly related to the ancestors carrying that component. What the program is saying is that the group of variants that characterizes the components "traveled together."
So in the case of the Chenini.
-It'll give the illusion of purity or continuity -It'll conceal ancestries they(Chenini) might actually have generated in the run. -It'll misrepresent the proportions of said ancestry in relationship other ancestries.
a couple of things cannot be inferred (granted I know this because I had done multiple runs and other tests but still), -The chenini K8 cluster is represents proportions of a real contributing population to other populations. -The Chenini completely lacks ancestry that should characterize North Africans.
Tukuler Member # 19944
posted
Ok gotcha (I think?). We on parallel train tracks.
My focus is K8 (olive) ancestry. Yours is narrowed down to the Chenini.
What can be said about K8? K8 appears exemplary, majority, and plurality in populations in Africa from the Sahra Desert to the Mediterranean Sea. It's age is at least as old as the most ancient sample having it. Natufian has 1%. On surer ground, Neolithic Levant shows 20%. Dunno how old WHG is but it's got a significant 4% of K8. (Obviously no recent Tamazight Chenini tribe yet existed.) (A single population is not any single discrete ancestry.) (A population is composed of various discrete ancestries.)
Looking again at Chenini they are ~90% K8 North African ancestry. I see no more illusion here than when looking at say CEU ADMIXTUREs whom most articles claim >99% purity.
ASIDE So in the case of the CEU.
-It'll give the illusion of purity or continuity -It'll conceal ancestries they(CEU) might actually have generated in the run. -It'll misrepresent the proportions of said ancestry in relationship other ancestries.
Who can look at the Chenini graph by itself and determine Chenini were founders of K8? That's very unlikely considering (pre-)history and linguistics. Those, and similar factors, must always inform conclusions on origins and exodes re genetic data. North African genomes form a 'cluster'. Tunisians in general are a distinct 'cluster' derived from the North African gene pool.
Note 'K-volution' of Tunisia re the rest of North Africa.
See Sened and Mzab go on to example other N Afr ancestries arising as isolated local ancestry (link).
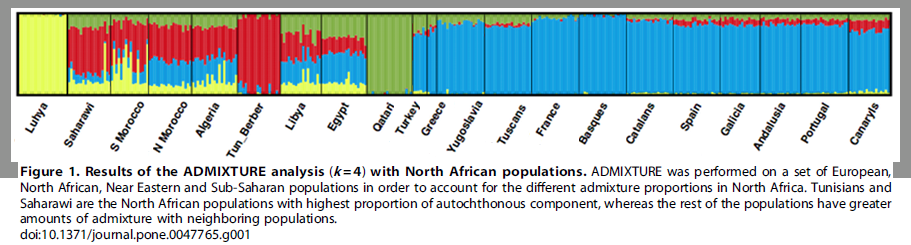
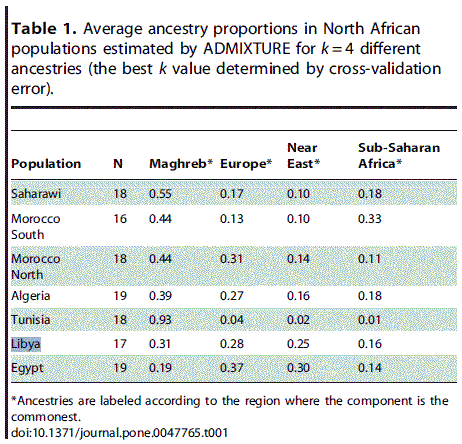
Our sample of Tunisian Berbers retains the highest amount of Maghrebi ancestry, without substantial evidence of admixture with sub-Saharan, European or Near Eastern populations. -- Henn 2012
The above, especially the latter's proportions of autochthon, Europe, Levant, and inner Africa are all confirmed in your 2019 K4-13 run. No?
The pros have each worded it their way. But me? All I can safely conclude from your 2019 graph is that whenever each individual ancestry or groups of related ancestry came together wherever they did, the people now living in Chenini Tunisia reveal
90% K8 Sahra-Mediterranean Africa ancesty
4% K4 Anatoli ancestry
3% K13 Sudan ancestry
2% K10 West Eurasian Villabruna-Iran ancestry
1% K1 SeneGambian ancestry (unless it's just the border)
whoever it came from, however they 'pitched in', or why.
Just to be clear, are you saying the above paragraphs are incorrect? That it only looks like Chenini have them in those proportions? That the geographies associated with the ancestries should not be used to label them?
I'm trying hard to get something out of this but I can't agree with any suggestion that denies what ADMIXTURE was designed to do. i.e., ferret out a population's ancestries by proportions.
If proportions of ancestries are misrepresentative then what good is ADMIXTURE in determining regional geographic ancestral components of individuals and the group that sets of individuals then belong to?
=-=-=
Congratulations on your blog article. More power to you!
Elmaestro Member # 22566
posted
quote:Just to be clear, are you saying the above paragraphs are incorrect? That it only looks like Chenini have them in those proportions? That the geographies associated with the ancestries should not be used to label them?
...Not incorrect but not all encompassing. More so than CEU for example, the Chenini Berbers were Consanguineous. so the 90% K8 Sahra-Mediterranean Africa ancestry you identified might just represent the shared variants among Chenini and not an actual preexisting population. The olive that is shared among the other populations are likely shared ancestry disguised by the Chenini component.
One again I'm not saying that the inferences are wrong. I'm just giving you more information. ADMIXTURE is doing it's job. But in the presence of a group of individuals who are highly related (in comparison to others), it'll basically look the same as it would if they were actual ancestors or the donors of whatever cluster they create. The equation in ADMIXTURE wasn't particularly designed to tell the difference in this case. This is why Admixture has built in functionality to designate supposed known Ancestors via supervised runs.
The reason why I want you to consider this fact is because of aDNA. If we add EEF, CHG, WHG and ANE populations to admixture, we no longer have "pure" CEU components. We see these components get absolutely shredded when we incorporate aDNA. Same with North African ancestry, without paleolithic and neolithic Moroccan aDNA Tunisian's look pure, but with them you see that they have Neolithic European and Near Eastern ancestry, and maybe SSA ancestry on top of the Early neolithic and paleolithic ancestries.
So a statement like this: The Amazigh sample from Chennini Douiret were subjected to the least amount of Admixture from Neighboring and invading populations
...Can be inferred from ADMIXTURE and would be correct. However. The 90% of the Chenini sample ancestry is representative of a distinct preexisting population who contributed ancestry to XYZ.
...Can be suggested by ADMIXTURE but may not necessarily be true because they are a relative genetic isolate (being consanguineous). And that 90% might just represent a group of variants you'd typically find among the Chenini sample themselves, not their ancestors etc.
Knowing this we can make an even more informed assessment.
Tukuler Member # 19944
posted
In light of American genome topic popularity. Amazing what a research project uncovers though not its objective at all.
This is from a Mainland SouthEast Asia article
Note 2 things not the aim of the research team.
The American exemplar Green K in so many regions. Maybe ANE related?
A little negro (Negrito) exemplar Grey K in darn near everybody except the AFR individuals. What is it? Some OoA subpop unaccounted for in neither the Mandenka nor the Mbuti donors?
Fig. 3. An ADMIXTURE analysis plot showing results for 6 hypothetical ancestral groups (K=6). Abbreviations for meta-populations are as follows: Ancient MSEA, Ancient Mainland Southeast Asians; AFR, present-day Africans; EUR, present-day Europeans; CAU, present-day Caucasians; ME, present-day Middle Easterners; NEG, present-day Andamanese Negritos; PAP, present-day Papuans; SAM, present-day Native Meso- and South Americans; ESEA, present-day East and Southeast Asians; SIB, present-day Siberians; CAS, present-day Central Asians; SAS, present-day South Asians; N, Neolithic; LN, Late Neolithic; PH, Protohistoric period; BA, Bronze Age; His., Historical period. The number of individuals for each population is indicated in brackets after the population name.

 posted
posted