quote: An absolute chronology for early Egypt using radiocarbon dating and Bayesian statistical modelling
The Egyptian state was formed prior to the existence of verifiable historical records. Conventional dates for its formation are based on the relative ordering of artefacts. This approach is no longer considered sufficient for cogent historical analysis. Here, we produce an absolute chronology for Early Egypt by combining radiocarbon and archaeological evidence within a Bayesian paradigm. Our data cover the full trajectory of Egyptian state formation and indicate that the process occurred more rapidly than previously thought. We provide a timeline for the First Dynasty of Egypt of generational-scale resolution that concurs with prevailing archaeological analysis and produce a chronometric date for the foundation of Egypt that distinguishes between historical estimates.
Michael Dee, David Wengrow, Andrew Shortland, Alice Stevenson, Fiona Brock, Linus Girdland Flink, Christopher Bronk Ramsey Published 4 September 2013.DOI: 10.1098/rspa.2013.0395
posted
This is an interesting paper. I found it very subjective because although they claim to have used radiocarbon dates in a Bayesian paradigm the results are suspect because Bayesian models usually produce the results you already held about the data you are evaluating, when you began the project.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
posted
Bayesian paradigm the results are suspect because Bayesian models usually produce the results you already held about the data you are evaluating, when you began the project.
This is a critical assessment.
Posts: 22234 | From: האם אינכם כילדי הכרית אלי בני ישראל | Registered: Nov 2010
| IP: Logged |
quote:Originally posted by Ish Gebor: Bayesian paradigm the results are suspect because Bayesian models usually produce the results you already held about the data you are evaluating, when you began the project.
This is a critical assessment.
In traditional evaluation of a piece of research literature you look at the researcher's hypothesis, results and statistical methods s/he used to determine the statistical significance of the research.
This is not the case in population genetics research; in this research you are evaluating statistical inferences based on the researchers beliefs about a set of data, instead of testing a hypothesis. As a result, the research contained in a population genetics article, reflects the views and beliefs already held by the researcher. Thusly, the statistical inferences will automatically support the views and beliefs held by the researcher; and any outliners that fail to support the researchers beliefs will not be mentioned in the research article/paper.
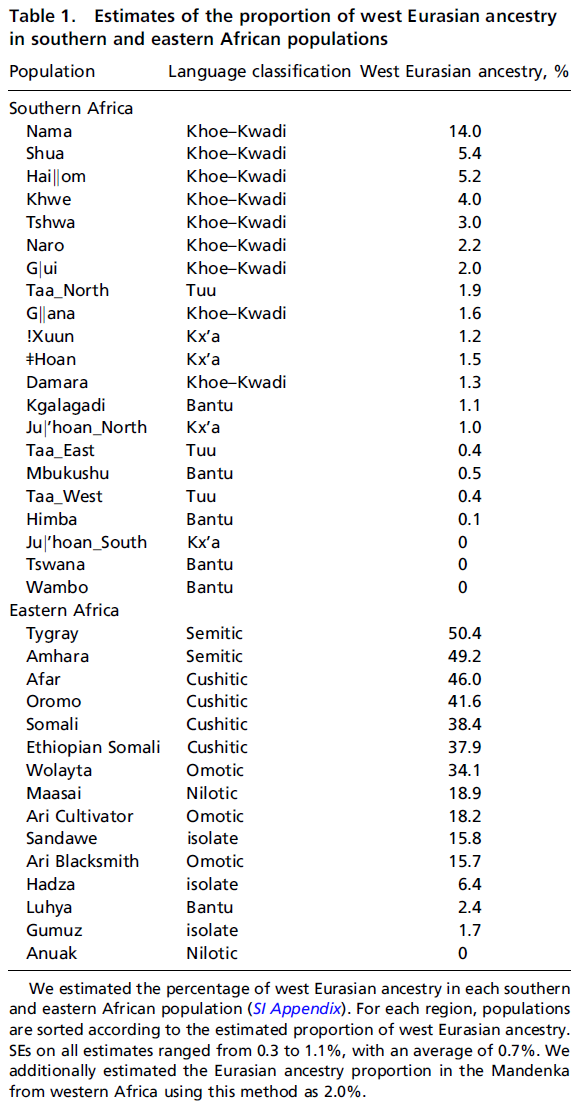
The most important reason for the disavowal of the Mota article was the finding that as much as 67% of the ancestry of West and Central African groups came from the Eurasian migrants.
This finding had to be eliminated because there is no evidence that Eurasians made their way to West and Central Africa. Since Eurasians were not in West and Central Africa, the so-called Eurasian admixture among these groups reflected the fact that the Eurasian genome, is really West and Central African not Eurasian.
The discovery of Eurasian "admixture" among West Africans is not a recent discovery. Pickrell et al (2014) found that the Mande people carry 2% Eurasian admixture. This supports the claim of the authors of the Mota article. .
. If it has been known since 2014 that West Africans were carrying Eurasian admixture the findings of, the authors of the Mota article that as much as 67% of the ancestry of West and Central African groups was "Eurasian" was not an error.
But like R1-V88, the "Eurasian" admixture, found among the West Africans in East, Central, West and South Africa is in reality African genomes passed onto the Eurasians when the Kushites migrated into Eurasia after the Great Flood. Other "Eurasian" genomes of African origin were deposited in Eurasia first by the Khoisan and later the Anu (Pygmies) that ruled Eurasia up to the Great Flood and finally the Kushites.
The first evidence of R1 in Western Europe dates back to 14,000 years ago in Italy, other European Hunter-gathers that carried this clade comes from Spain, Samara and Germany. They carried R1b1, which Kivisild (2017), is a "relative" of V88.
The other so-called Hunter-gatherer Eurasian genes in Europe appear first in Iberia, especially Y-Chromosome G, and were taken eastward into the Steppe.
The first farmers in Europe were the Bell Beaker people in Iberia. Bell Beaker originated in Morocco so these people were also Africans carrying G and R haplogroups.
This would explain the presence of so-called Eurasian genes among the Abusir mummies. The Abusir mummies make it clear the so-called Eurasian genes were in fact native African genes. .
.
The Agro-pastoral culture was introduced into Europe by the Kushite tribes that lived in Anotolia. These tribes include the Hati, Kaska, Kassite and etc. They migrated into the Steppes and migrated westward into Western Europe.
To disguise the presence of African genes in places where they are not desired to be found researchers write programs that mask these genes out of the results.
In conclusion, most population genetics studies are pseudo-experimental research papers. An Experimental design refers to how participants are allocated to the different conditions (or Individual Variable levels) in an experiment. In population genetics research there is no treatment and control baseline groups that can be compared. The absence of a control and treatment groups in population genetics research makes the research method a pseudo-experimental design. It is using a pseudo-experimental design because the geneticists is evaluating statistical inferences based on the researchers beliefs about a set of data, instead of testing a hypothesis. As a result, the research contained in a population genetics article, reflects the views and beliefs already held by the researcher.
Reference:
Joseph K. Pickrell, Nick Patterson, Po-Ru Loh, Mark Lipson, Bonnie Berger, Mark Stoneking, Brigitte Pakendorf, and David Reich.(2014). Ancient west Eurasian ancestry in southern and eastern Africa. PNAS 2014 111 (7) 2632-2637.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
quote:Originally posted by Ish Gebor: Hence: bias Bayes(-ian) modeling.
Not only is it bias but,it is not science. The authors using Bayesian statistics never form a hypothesis and test the hypothesis, they only find the results they are looking for.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
quote:Originally posted by Clyde Winters: But like R1-V88, the "Eurasian" admixture, found among the West Africans in East, Central, West and South Africa is in reality African genomes passed onto the Eurasians when the Kushites migrated into Eurasia after the Great Flood.
Ish Gebor you asked me why I argue against Clyde. It's because he doesn't have a degree in African Studies and he makes bizarre claims about Kushite migrations due to "Great Floods" Professors of African history don't make up things like this.
Posts: 42921 | From: , | Registered: Jan 2010
| IP: Logged |
quote:Originally posted by Clyde Winters: But like R1-V88, the "Eurasian" admixture, found among the West Africans in East, Central, West and South Africa is in reality African genomes passed onto the Eurasians when the Kushites migrated into Eurasia after the Great Flood.
Ish Gebor you asked me why I argue against Clyde. It's because he doesn't have a degree in African Studies and he makes bizarre claims about Kushite migrations due to "Great Floods" Professors of African history don't make up things like this.
Stupid Euronut, you don't know anything about me. I earned a BA and MA from the University of Illinois-Urbana, in only 4 years. I did have a minor in African studies. .
.
The Graduate classes were Seminars so I had to write many research papers, eventhough I was only an Undergraduate my first three (3) at Illinois.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
posted
And they taught you there was a migration of Kushites inton Eurasia due to a great flood???
Posts: 42921 | From: , | Registered: Jan 2010
| IP: Logged |
posted
While I agree that there are obvious biases in the scientific community which may/may not influence statistic models and such, I'd have to ask that we be a lil more analytical and a lil less critical of these statistical concepts. Calling Bayesian approaches or K-means, "biased" just doesn't cut it and makes our community look in-denial, and out of touch....
Can I suggest we put a lil more effort into showing how, the individual study or method can yield undesirable or inaccurate results? It isn't that hard to break down how Bayes law should be applied or why we should or shouldn't use Bayesian stats for probability in population growth in this (or whatever) study. That approach will both help incite meaningful discussion and help less versed people understand the science behind statistical modeling etc. so we all can know what we're looking at and why.
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Elmaestro: While I agree that there are obvious biases in the scientific community which may/may not influence statistic models and such, I'd have to ask that we be a lil more analytical and a lil less critical of these statistical concepts. Calling Bayesian approaches or K-means, "biased" just doesn't cut it and makes our community look in-denial, and out of touch....
Can I suggest we put a lil more effort into showing how, the individual study or method can yield undesirable or inaccurate results? It isn't that hard to break down how Bayes law should be applied or why we should or shouldn't use Bayesian stats for probability in population growth in this (or whatever) study. That approach will both help incite meaningful discussion and help less versed people understand the science behind statistical modeling etc. so we all can know what we're looking at and why.
You have to be critical in reading any piece of research literature. You can not take any piece of research literature as valid or invalid until after you critically read the paper.
Probability means the the extent to which something is probable; the likelihood of something happening or being the case. This means that you are making guess estimates of a phenomena instead of hypotheses testing.
As a result, you can not take any piece of research literature solely on face value.
Below I discuss a tool you can use to Evaluate population genetics articles.
Many people dont know how to evaluate population genetics articles, because they are expost facto research based on statistical infererences or the beliefs of the researcher supported by statistics. As a result, researchers can not judge the difference between an ad hominid and legitimate discussion of the doxa behind a researchers research.
In traditional evaluation of a piece of research literature you look at the researcher's hypothesis, results and statistical methods s/he used to determine the statistical significance of the research.This is not the case in population genetics research; in this research you are evaluating statistical inferences based on the researchers beliefs about a set of data, instead of testing a hypothesis. As a result, the research contained in a population genetics article, reflects the views and beliefs already held by the researcher. Thusly, the statistical inferences will automatically support the views and beliefs held by the researcher; and any outliners that fail to support the researchers beliefs will not be mentioned in the research article/paper.
Here we will ask the question: How do you evaluate population genetics research? We will attempt to look at the doxa that may influence a geneticist's research and the constructs that should be considered when evaluating this knowledge base.
Firstly, we assume that any article or book written by an establishment member of the academe is reliable and valid. A piece of research full of valid scientific and/or historical truths--erudite scholarship and impeccable research based on the scientific method.
The scientific method is based on hypotheses testing. Hypotheses testing means that a researcher forms a hypothesis and test the hypothesis using a series of quantitative or qualitative statistical methods to determine the statistical significance of the hypothesis being tested. The scientific method is based on experimentation to test a hypothesis .
Population geneticists usually do not test hypotheses. They make inferences about data based on Bayesian statistical inferences. They do not use statistical methods to determine the statistical significance of a hypothesis, they use statistics to describe data being reviewed by the researcher based on the beliefs the researcher already holds about the data being reviewed..
Population genetics is a type of Expost facto research. Expost facto research design is a quasi-experimental type of study examining how an independent variable, present prior to the research study, affects a dependent variable.
Whereas the subjects in experimental research are randomly selected, the participants in Expost facto research , are not randomly selected or assigned.The genome of the research subjects is examined to determine the haplotypes and haplogroups carried by the participants in the study.
In population genetics research the researcher uses the Bayesian inference method of statistical inference. Bayesian statistical method, is a subjective research design/method that provides a rational method of updating the researcher's beliefs.
Since, the results of a Bayesian statistical analysis are a series of beliefs based on statistical inferences, the results can not stand alone. This is due to the reality, that any results, reported by a researcher are only a series of inferences based on the researchers belief about a phenomena backed up by a series statistical results. If the results are published without corresponding evidence from archaeology, anthropology, linguistics and or craniometrics the inferences are pure conjecture, because they reflect the attitudes already held by the researcher, confirmed by data selected by the researcher to support his or her beliefs.
There is a sociological basis behind how a researcher interprets data. Sociological research indicates that there are unconscious cognitive structures within each individual. Cognitive structures that hold the idealistic view of members of the academe that determine how they perceive "reality". These structures are called doxa.
Commenting on these schema Berlinerblau (1999) noted that "These types of theories share the assumption that human beings know things that they do not even know that they know; that they "possess" knowledge about the world which exists in some sort of cognitive substrate, beyond the realm of discourse" (p.106).Wacquant (1995) says that doxa is " a realm of implicit and unstated beliefs".
Given the research suggesting that doxa exist, support the view that some researchers allow their hatred of multiculturalism, ethnic prejudice and racism to define their discourse, teaching and writing about themes relating to groups " other" ,than their own cultural and ethnic group . Moreover, it suggest that when topics such as Eurasian and African haplogroups, Afrocentrism, African origins of the Dravidians and etc., is attacked by members of the academe, these academics are supported by the "establishment" without any reservation, or test of the validity of their claims. In fact, it appears that doxic assumptions relating to the validity of Afrocentrism, back migration of so-called Eurasian genes into Africa, rcent African origens of Dravidians and Dravidian origin of the Indus Valley Civilization obviates critique of the academics that disparage these themes. Due to Doxa you can state a researchers attitude toward a historical, genetic or anthropological concept and theorems without the statement being an ad hominem
To evaluate research literature a student should know the varied research methods.A student evaluating a piece of population genetics literature must understand that the researcher is conducting an expost facto method of research that does not involve hypotheses testing .Given the nature of Bayesian inferences, you can not determine the validity and reliability of a piece of genetics research literature based on the statistical significance of the data. What you must do is look at the research article and ask yourself a series of questions regarding the article's validity and reliability. Below is a series of questions to evaluate population genetics articles.
Checklist used to analyze a Population Genetics Papers
Answer the following questions relating to this research article below, or on a separate sheet of paper.
1. What was the rationale for the study, that is, what led up to it? Yes on page___ ,paragraph____ _,lines________ No_______ 2. Why do the authors believe that this problem is significant? Yes on page___ ,paragraph____ _,lines________ No_______ 3. What was the purpose of the study, that is , what did it intend to accomplish? Yes on page___ ,paragraph____ _,lines________ No_______ 4. What was the hypothesis of the study? Yes on page___ ,paragraph____ _,lines________ No_______ 5. What were the participants major characteristics? Yes on page___ ,paragraph____ _,lines________ No_______ 6. Does the review of literature indicate previous research in the area associated with the article? Yes on page___ ,paragraph____ _,lines________ No_______ 7. What type of study is reported in this article? Yes on page___ ,paragraph____ _,lines________ No_______ 8. Was the sample randomly selected? Yes on page___ ,paragraph____ _,lines________ No_______ 9. What was the instrument? Yes on page___ ,paragraph____ _,lines________ No_______ 10. What were the major steps involved in the treatment? Yes on page___ ,paragraph____ _,lines________ No_______ 11. How were the variables tested? Yes on page___ ,paragraph____ _,lines________ No_______ 12. According to the author(s) how successful was the treatment? Yes on page___ ,paragraph____ _,lines________ No_______ 13. What factors could equally account for the student tests results? Yes on page___ ,paragraph____ _,lines________ No_______ 14. What problems, if any, do you detect in the study? Yes on page___ ,paragraph____ _,lines________ No_______
15. Do the results of analysis agree with the authors objectives and expectations? Yes on page___ ,paragraph____ _,lines________ No_______
16. What other interpretations could be made from the data? Yes on page___ ,paragraph____ _,lines________ No_______
17. Is there archaeological, craniometric and or linguistic evidence that supports the research findings Yes on page___ ,paragraph____ _,lines________ No_______
The Evaluator should read the article twice. The first reading of the article is brief.
Next make a close reading of the article. The close read should involve the Evaluator in underlining key details in the article, while making annotations of important points in the text. During the second reading of the text the Evaluator will assess the research article using the checklist above.Since the Bayesian statistics used for the study will support the inferences of the Researcher the answers for the majority of the checklist will be yes.
The key question in determining the validity of the research will be question 17. If the researcher only has Bayesian statistical inferences supporting the research study , the inferences made in the research article , may not be representative of actual past population events.
In summary, the validity and reliability of a piece of genetics research literature does not demand the Evaluator of a piece of literature to provide counter evidence all they need to do is evaluate the research using the checklist above. If the answer to most of these questions is no, the research is unreliable and lacks any validity.
The key question on the checklist is question 17. To confirm the validity of the archaeological, craniometric and etc., data , the Evaluator should be knowledgeable about the archaeology of the area where the population movement has been inferred to have taken place.In this way you can determine if the Bayesian inferences correspond to the archaeological, craniometric, linguistic data associated with the geographical area where the population movement is suppose to have occur .
The major problem with most genetics literature which invalidates the research dealing with ancient population movements is that it is not supported by the ancientDNA, archaeological and/ or craniometric data. This is why many of theories about the ancient populations of Europe and alledged back migrations are usually over turned once researchers examine the ancient DNA.
Many geneticist are beginning to attempt to match contemporary populations with ancient Eurasian populations by masking data they don't want the readers to know about or changing the names of haplogroups to disguise the African origin of many Eurasian genes.
To disguise the African ancestry of the ancient Europeans Geno-Hamiticists change the name/number of African haplogroups to differentiate them from Europeans carrying the same haplogroup. R1b1 and Rlb1a were clades belonging to V88.
R1b1 and R1b1a do not change just because you give it a different number. Below is Cruciani et al (2010).
.
Researchers give ancient DNA what ever number they wish. For example Haak et al (2015) claims I0124 (Samara_HG) is R1b1, while Iain Mathieson et al 2017, claims I0124 is R1b1a1a. How can the same individual be assigned two different R1 clades. The same thing is obvious in labeling I0124 (Samara_HG) R1b1 ( L278) and I0410 (Spain_EN) R1b1 (M415).
This is nothing but Trickology, an attempt to make it appear the individuals were not Sub-Saharan African.
quote:Originally posted by Clyde Winters:[...] Many people dont know how to evaluate population genetics articles, because they are expost facto research based on statistical infererences or the beliefs of the researcher supported by statistics. As a result, researchers can not judge the difference between an ad hominid and legitimate discussion of the doxa behind a researchers research.
In traditional evaluation of a piece of research literature you look at the researcher's hypothesis, results and statistical methods s/he used to determine the statistical significance of the research.This is not the case in population genetics research; in this research you are evaluating statistical inferences based on the researchers beliefs about a set of data, instead of testing a hypothesis. As a result, the research contained in a population genetics article, reflects the views and beliefs already held by the researcher. Thusly, the statistical inferences will automatically support the views and beliefs held by the researcher; and any outliners that fail to support the researchers beliefs will not be mentioned in the research article/paper.
Ok, one thing I'd like to point out, is that genetics is at least 70% statistics... As opposed to Molecular Biology for example where you can set up a control based on a hypothesis to analyze causal or correlational relationships, stat based studies uses the result of whatever equation or function (now in the forms of a program/app) to get an associative or statistical hypothesis, which is why the results of a single equation or statistical problem cannot determine the outcome of a Genetic study. Every time a dataset is ran through Admixture we get a hypothesis, everytime we use Eigenstrat/Smart PCA we get a natural hypothesis, everytime we use structure we gain a natural hypothesis. There isn't much or many ways you can do statistical studies as a researcher... openly making an inference about the relationship you expect to see and test for is restrictive and can lead to more biased or less informative statistical modeling... You should know this.
Here we will ask the question: How do you evaluate population genetics research? We will attempt to look at the doxa that may influence a geneticist's research and the constructs that should be considered when evaluating this knowledge base.
Firstly, we assume that any article or book written by an establishment member of the academe is reliable and valid. A piece of research full of valid scientific and/or historical truths--erudite scholarship and impeccable research based on the scientific method.
The scientific method is based on hypotheses testing. Hypotheses testing means that a researcher forms a hypothesis and test the hypothesis using a series of quantitative or qualitative statistical methods to determine the statistical significance of the hypothesis being tested. The scientific method is based on experimentation to test a hypothesis . No, the statistical significance estimates the validity of the RESULT, not the hypothesis. This isn't 4th grade science Population geneticists usually do not test hypotheses. They make inferences about data based on Bayesian statistical inferences. They do not use statistical methods to determine the statistical significance of a hypothesis, they use statistics to describe data being reviewed by the researcher based on the beliefs the researcher already holds about the data being reviewed.. what you say at the end here might be true, but you have to point out how for EACH study... cuz for one, we don't find the P value for a hypothesis, EVER. And two, we all use the same equations in different ways and sometimes get different results. When and how these models, functions, programs or equations are misused or can be used better varies based on the study. So when you read Peer reviews where other researchers tear an author/editor/researcher a new asshole; that's part of the process... After the papers are published and the public scrutinizes; thats part of the process... If you can complain and cry bias, you should be able to point out how, why and what these guys can do better, be a part of the process. Population genetics is a type of Expost facto research. Expost facto research design is a quasi-experimental type of study examining how an independent variable, present prior to the research study, affects a dependent variable. I wouldn't call it "Expost facto," but the dependent variables are applied or set within each statistical problem, whether its part of the equation or presents itself as a constant, their's absolutely nothing wrong with this in the study of genetics.
Whereas the subjects in experimental research are randomly selected, the participants in Expost facto research , are not randomly selected or assigned.The genome of the research subjects is examined to determine the haplotypes and haplogroups carried by the participants in the study. counter this by pointing out the biased sampling, this isn't a universal issue. In population genetics research the researcher uses the Bayesian inference method of statistical inference. Bayesian statistical method, is a subjective research design/method that provides a rational method of updating the researcher's beliefs.
Since, the results of a Bayesian statistical analysis are a series of beliefs based on statistical inferences, the results can not stand alone. This is due to the reality, that any results, reported by a researcher are only a series of inferences based on the researchers belief about a phenomena backed up by a series statistical results. If the results are published without corresponding evidence from archaeology, anthropology, linguistics and or craniometrics the inferences are pure conjecture, because they reflect the attitudes already held by the researcher, confirmed by data selected by the researcher to support his or her beliefs. Give us an example of Bayesian problem that would lead to preconcieved result, or be quiet about it, it shouldn't take that long [...] Many geneticist are beginning to attempt to match contemporary populations with ancient Eurasian populations by masking data they don't want the readers to know about or changing the names of haplogroups to disguise the African origin of many Eurasian genes.
To disguise the African ancestry of the ancient Europeans Geno-Hamiticists change the name/number of African haplogroups to differentiate them from Europeans carrying the same haplogroup. R1b1 and Rlb1a were clades belonging to V88.
R1b1 and R1b1a do not change just because you give it a different number. Below is Cruciani et al (2010).
.
Researchers give ancient DNA what ever number they wish. For example Haak et al (2015) claims I0124 (Samara_HG) is R1b1, while Iain Mathieson et al 2017, claims I0124 is R1b1a1a. How can the same individual be assigned two different R1 clades. The same thing is obvious in labeling I0124 (Samara_HG) R1b1 ( L278) and I0410 (Spain_EN) R1b1 (M415).
This is nothing but Trickology, an attempt to make it appear the individuals were not Sub-Saharan African.
The rest of your excerpt is built on fallacy, at the end of the day, like I Explained, you HAVE the Ability to point out and explain in specific analytic detail, What, Why and How whatever equation or model is being misused. You're basically saying Keita, Tishkoff, Tekola-ayele, killick are all dishonest biased researchers for using statistical modeling whether bayesian, qNewton methods or whatever to do "expost facto" style research.
Do all of us a favor and get the raw files for the R1b1 specimen, And report the variants so we as a community can see and know for a fact or even help you prove that these people are V88 using Isogg... If you can't do such a thing or link us to the study that confirms without question that these people belong, don't presume that their hiding or omitting information because they're racists... that is a crippling mindset and it puts us all back in time.
I won't respond in this thread unless you give an example of how Bayes law in the OP was incorrectly applied or is erroneous in general... Also, Can you please shorten your post's and try to prove a point before building on the foundation of an fallible statement please.
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Clyde Winters: But like R1-V88, the "Eurasian" admixture, found among the West Africans in East, Central, West and South Africa is in reality African genomes passed onto the Eurasians when the Kushites migrated into Eurasia after the Great Flood.
Ish Gebor you asked me why I argue against Clyde. It's because he doesn't have a degree in African Studies and he makes bizarre claims about Kushite migrations due to "Great Floods" Professors of African history don't make up things like this.
1) You are too dumb to understand the Bayesianmodel.
2) You don't know more about Africana than he does.
3) All these back migrations you claim are in direct conflict and contradiction with Africana. They are born in white supremacy and troll science, going back to the early days of armchair anthropology.
4) So where is your degree?
Posts: 22234 | From: האם אינכם כילדי הכרית אלי בני ישראל | Registered: Nov 2010
| IP: Logged |
quote:Originally posted by Elmaestro: While I agree that there are obvious biases in the scientific community which may/may not influence statistic models and such, I'd have to ask that we be a lil more analytical and a lil less critical of these statistical concepts. Calling Bayesian approaches or K-means, "biased" just doesn't cut it and makes our community look in-denial, and out of touch....
Can I suggest we put a lil more effort into showing how, the individual study or method can yield undesirable or inaccurate results? It isn't that hard to break down how Bayes law should be applied or why we should or shouldn't use Bayesian stats for probability in population growth in this (or whatever) study. That approach will both help incite meaningful discussion and help less versed people understand the science behind statistical modeling etc. so we all can know what we're looking at and why.
I obviously meant it sarcastically. However, subliminal.
This paper is important to understand, in the light of the latest Abu Sir "sampled" mummies.
Posts: 22234 | From: האם אינכם כילדי הכרית אלי בני ישראל | Registered: Nov 2010
| IP: Logged |
quote:Originally posted by Clyde Winters: Many people dont know how to evaluate population genetics articles, because they are expost facto research based on statistical infererences or the beliefs of the researcher supported by statistics. As a result, researchers can not judge the difference between an ad hominid and legitimate discussion of the doxa behind a researchers research.
In traditional evaluation of a piece of research literature you look at the researcher's hypothesis, results and statistical methods s/he used to determine the statistical significance of the research.This is not the case in population genetics research; in this research you are evaluating statistical inferences based on the researchers beliefs about a set of data, instead of testing a hypothesis. As a result, the research contained in a population genetics article, reflects the views and beliefs already held by the researcher. Thusly, the statistical inferences will automatically support the views and beliefs held by the researcher; and any outliners that fail to support the researchers beliefs will not be mentioned in the research article/paper.
Ok, one thing I'd like to point out, is that genetics is at least 70% statistics... As opposed to Molecular Biology for example where you can set up a control based on a hypothesis to analyze causal or correlational relationships, stat based studies uses the result of whatever equation or function (now in the forms of a program/app) to get an associative or statistical hypothesis, which is why the results of a single equation or statistical problem cannot determine the outcome of a Genetic study. Every time a dataset is ran through Admixture we get a hypothesis, everytime we use Eigenstrat/Smart PCA we get a natural hypothesis, everytime we use structure we gain a natural hypothesis. There isn't much or many ways you can do statistical studies as a researcher... openly making an inference about the relationship you expect to see and test for is restrictive and can lead to more biased or less informative statistical modeling... You should know this.
Stop making stuff up. You dont get a hypothesis when you run an admixture program what you get a is correlational study comparing the SNPs associated with the haplogroups in your study. The bias comes from the researcher masking out clades they dont want to appear in the results of their study, and including alleged Eurasian haplogroups. The aim of these programs is to refine identification of an individuals genetic profile based on the SNPs in assigned haplogroups.
Here we will ask the question: How do you evaluate population genetics research? We will attempt to look at the doxa that may influence a geneticist's research and the constructs that should be considered when evaluating this knowledge base.
Firstly, we assume that any article or book written by an establishment member of the academe is reliable and valid. A piece of research full of valid scientific and/or historical truths--erudite scholarship and impeccable research based on the scientific method.
The scientific method is based on hypotheses testing. Hypotheses testing means that a researcher forms a hypothesis and test the hypothesis using a series of quantitative or qualitative statistical methods to determine the statistical significance of the hypothesis being tested. The scientific method is based on experimentation to test a hypothesis . No, the statistical significance estimates the validity of the RESULT, not the hypothesis. This isn't 4th grade science
LOL. Science is based on hypothesis testing. Population genetics is based on making a correlation between single-nucleotide polymorphism, at a specific position in the genome, compared to SNPs in aDNA to establish its relationship to contemporary haplogroup profiles.
In Genetic studies there is no statistical significance the results are given as percentages. In statistics, a number that expresses the probability that the result of a given experiment or study could have occurred purely by chance. To reject the null hypothesis you establish a significance level of p<.05 or p<.01. In genetic studies you simply report the percentage of a particular clade carried by individuals in a study.
Population geneticists usually do not test hypotheses. They make inferences about data based on Bayesian statistical inferences. They do not use statistical methods to determine the statistical significance of a hypothesis, they use statistics to describe data being reviewed by the researcher based on the beliefs the researcher already holds about the data being reviewed..
what you say at the end here might be true, but you have to point out how for EACH study... cuz for one, we don't find the P value for a hypothesis, EVER. And two, we all use the same equations in different ways and sometimes get different results. When and how these models, functions, programs or equations are misused or can be used better varies based on the study. So when you read Peer reviews where other researchers tear an author/editor/researcher a new asshole; that's part of the process... After the papers are published and the public scrutinizes; thats part of the process... If you can complain and cry bias, you should be able to point out how, why and what these guys can do better, be a part of the process.
The equations used by geneticists is just bs to make their papers look scientific. In the end the only thing they report in their findings are percentages of the haplogroups carried by individuals. What they can do better is read the archeology before they make concliusions based solely on Geno-Hamiticism.
Population genetics is a type of Expost facto research. Expost facto research design is a quasi-experimental type of study examining how an independent variable, present prior to the research study, affects a dependent variable. I wouldn't call it "Expost facto," but the dependent variables are applied or set within each statistical problem, whether its part of the equation or presents itself as a constant, their's absolutely nothing wrong with this in the study of genetics.
Youre right this is okay in genetic studies because the equations are just for window dressing. Geneticists mainly report the percentage individuals carry of a specific haplogroup.
Whereas the subjects in experimental research are randomly selected, the participants in Expost facto research , are not randomly selected or assigned.The genome of the research subjects is examined to determine the haplotypes and haplogroups carried by the participants in the study. counter this by pointing out the biased sampling, this isn't a universal issue.
The bias comes from changing the name of haplogroups which are African in origin, or simply failing to acknowledge the African origin of a clade. For example, Haak et al acknowledge that the hunter-gathers were R1b1, but not R1b-M269. Yet they failed to admit that these clades were relatives to V88.
In population genetics research the researcher uses the Bayesian inference method of statistical inference. Bayesian statistical method, is a subjective research design/method that provides a rational method of updating the researcher's beliefs.
Since, the results of a Bayesian statistical analysis are a series of beliefs based on statistical inferences, the results can not stand alone. This is due to the reality, that any results, reported by a researcher are only a series of inferences based on the researchers belief about a phenomena backed up by a series statistical results. If the results are published without corresponding evidence from archaeology, anthropology, linguistics and or craniometrics the inferences are pure conjecture, because they reflect the attitudes already held by the researcher, confirmed by data selected by the researcher to support his or her beliefs. Give us an example of Bayesian problem that would lead to preconcieved result, or be quiet about it, it shouldn't take that long [...]
You are right it is easy to illustrate that using Bayesian statistics researchers get the results they are looking for no matter what statistical model they use. To illustrate this phenomena we will look at Massive migration from the steppe is a source for Indo-European languages in Europe by Wolfgang Haak et al. In the introduction the authors state the purpose of their study: [quote] We used this technology to study population transformations in Europe.
This indicates that Haak et al was doing a descriptive study of haplogroups carried by ancient Europeans. To obtain results the authors compared the SNPs of aDNA, to contemporary clade profiles to determine what haplogroup they carried.
quote: We determined that 34 of the 69 newly analyzed individuals were male and used 2,258 Y chromosome SNPs targets included in the capture to obtain high resolution Y chromosome haplogroup calls (SI4). Outside Russia, and before the Late Neolithic period, only a single R1b individual was found (early Neolithic Spain) in the combined literature (n=70). By contrast, haplogroups R1a and R1b were found in 60% of Late Neolithic/Bronze Age Europeans outside Russia (n=10), and in 100% of the samples from European Russia from all periods (7,500-2,700 BCE; n=9). R1a and R1b are the most common haplogroups in many European populations today18,19, and our results suggest that they spread into Europe from the East after 3,000 BCE. Two hunter-gatherers from Russia included in our study belonged to R1a (Karelia) and R1b (Samara), the earliest documented ancient samples of either haplogroup discovered to date. These two hunter-gatherers did not belong to the derived lineages M417 within R1a and M269 within R1b that are predominant in Europeans today18,19, but all 7 Yamnaya males did belong to the M269 subclade18 of haplogroup R1b.
Above the authors report their findings. They tell us what the ancient European haplogroups were. They admit R1b (Samara) was not M269. As you can see there is no examination of an independent variable, affecting a dependent variable, they only report the percentages of haplogroups carried by the ancient Europeans. This is not science, they are just describing the clades carried by the varied ancient Europeans. Haak et al in their conclusion claim that their study
quote: [i] Our results provide new data relevant to debates on the origin and expansion of IndoEuropean languages in Europe (SI11). Although ancient DNA is silent on the question of the languages spoken by preliterate populations, it does carry evidence about processes of migration which are invoked by theories on Indo-European language dispersals. Such theories make predictions about movements of people to account for the spread of languages and material culture. The technology of ancient DNA makes it possible to reject or confirm the proposed migratory movements, as well as to identify new movements that were not previously known. The best argument for the Anatolian hypothesis27 that Indo-European languages arrived in Europe from Anatolia ~8,500 years ago is that major language replacements are thought to require major migrations, and that after the Early Neolithic when farmers established themselves in Europe, the population base was likely to have been so large as to be impervious to subsequent turnover27,28
This conclusion is not supported by the genomic evidence, and even the authors admit that ancient DNA is silent on the question of the languages spoken by preliterate populations, . Although we have no data on the languages spoken by the European hunter-gathers, the Anatolians who spread the agro-pastoral traditions into Europe spoke non Indo-European languages. In fact, the textual evidence makes it clear the Hitites the first so-called Indo-Europeans in Anatolia did not speak an I-E language.
The culture traits of the CHG : horseback riding , meyallurgy and etc., are of Kushite, not Indo-European in origin. The major problem with the theory Haak et al, is that the earliest rulers of the land where these culture traits originated were Kaska and Hatti speakers who spoke a non-IE languages called Khattili. The gods of the Hattic people were Kasku and Kusuh (< Kush).
The Hattic people, may be related to the Hatiu, one of the Egyptian Delta Tehenu tribes. Many archaeologist believe that the Tehenu people were related to the C-Group people. The Hattic language is closely related to African and Dravidian languages for example:
English Hattic Egyptian Malinke (Mande language)
powerful ur wr'great,big' fara
protect $uh swh solo-
head tup tp tu 'strike the head'
up,upper tufa tp dya, tu 'raising ground'
to stretch put pd pe, bamba
to prosper falfat -- find'ya
pour duq --- du 'to dispense'
child pin,pinu den
Mother na-a -- na
lord sa -- sa
place -ka -ka
It is clear that genetic studies such as Haak et al, only report the percentages of haplogroups carried by individuals in their study, and the results only verify the beliefs already held by the authors. This is obvious when Haak et al, declares the agro-patoral migrants from Anatolia were I-E speakers when the linguistic evidence shows opposite.
Many geneticist are beginning to attempt to match contemporary populations with ancient Eurasian populations by masking data they don't want the readers to know about or changing the names of haplogroups to disguise the African origin of many Eurasian genes.
To disguise the African ancestry of the ancient Europeans Geno-Hamiticists change the name/number of African haplogroups to differentiate them from Europeans carrying the same haplogroup. R1b1 and Rlb1a were clades belonging to V88.
R1b1 and R1b1a do not change just because you give it a different number. Below is Cruciani et al (2010).
.
Researchers give ancient DNA what ever number they wish. For example Haak et al (2015) claims I0124 (Samara_HG) is R1b1, while Iain Mathieson et al 2017, claims I0124 is R1b1a1a. How can the same individual be assigned two different R1 clades. The same thing is obvious in labeling I0124 (Samara_HG) R1b1 ( L278) and I0410 (Spain_EN) R1b1 (M415).
This is nothing but Trickology, an attempt to make it appear the individuals were not Sub-Saharan African.
The rest of your excerpt is built on fallacy, at the end of the day, like I Explained, you HAVE the Ability to point out and explain in specific analytic detail, What, Why and How whatever equation or model is being misused. You're basically saying Keita, Tishkoff, Tekola-ayele, killick are all dishonest biased researchers for using statistical modeling whether bayesian, qNewton methods or whatever to do "expost facto" style research.
I never said the studies were dishonest, I said they illustrate the opinions already held by the researcher. This is obvious by the fact they only include in the study SNPs from haplogroups they associate with Eurasians or Africans. They mask out haplogroups they don't want to appear in their study.
The statistics are bs. All they are doing is comparing the SNPs of aDNA, to the profiles of contemporary clades to categorize the haplogroups of ancient individuals. The statistics make it appear the study is significant when really the researchers are only conducting correlational studies.
Do all of us a favor and get the raw files for the R1b1 specimen, And report the variants so we as a community can see and know for a fact or even help you prove that these people are V88 using Isogg... If you can't do such a thing or link us to the study that confirms without question that these people belong, don't presume that their hiding or omitting information because they're racists... that is a crippling mindset and it puts us all back in time.
LOL. Getting the raw files for the R1b1 specimen and examining the variants based on ISOGG is a waste of time. Look at how they have changed the nomenclature of V88 and its subclade at least four times since 2010, to ensure that R1b1, is only associated with M269 , when Africans carried the same clade.
I won't respond in this thread unless you give an example of how Bayes law in the OP was incorrectly applied or is erroneous in general... Also, Can you please shorten your post's and try to prove a point before building on the foundation of an fallible statement please. [/QB]
LOL. My statements are not erroneous. I repeat Researchers give ancient DNA what ever number they wish. For example Haak et al (2015) claims I0124 (Samara_HG) is R1b1, while Iain Mathieson et al 2017, claims I0124 is R1b1a1a. How can the same individual be assigned two different R1 clades. The same thing is obvious in labeling I0124 (Samara_HG) R1b1 ( L278) and I0410 (Spain_EN) R1b1 (M415).
This is nothing but Trickology, an attempt to make it appear the individuals were not Sub-Saharan African.
Without p<.05 or p<.01 in genetic studies they can not have statistical significance. Population genetic studies are simple correlational studies comparing the SNPs of varied genomes of individuals so they can be assigned to a particular clade. This is why Bayesian studies are worthless without archaeological and linguiistic evidence to support the findings.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
posted
Explain why Bayes law is bullshit or shouldn't be applied in the OP or stay in the cut. I wont chase you around while you reinvent the meaning of scientific concepts, you KNOW for a fact that Hg assignments are binary and that you have to have a mutation indicative of R1B1 to be R1b1a1a. and though the bin Nomenclature can change, the mutations stay the same (as well as the relationship between them) so half of your argument is already out of the window.... why mislead your people like that?
Break down Bayes theorem and how it is being misused in the OP, While you're at it, explain why Bayesian stats fail in ADMIXTURE as well as STRUCTURE, etc... It ain't that hard, put up or shut up.
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Elmaestro: While I agree that there are obvious biases in the scientific community which may/may not influence statistic models and such, I'd have to ask that we be a lil more analytical and a lil less critical of these statistical concepts. Calling Bayesian approaches or K-means, "biased" just doesn't cut it and makes our community look in-denial, and out of touch....
Can I suggest we put a lil more effort into showing how, the individual study or method can yield undesirable or inaccurate results? It isn't that hard to break down how Bayes law should be applied or why we should or shouldn't use Bayesian stats for probability in population growth in this (or whatever) study. That approach will both help incite meaningful discussion and help less versed people understand the science behind statistical modeling etc. so we all can know what we're looking at and why.
I obviously meant it sarcastically. However, subliminal.
This paper is important to understand, in the light of the latest Abu Sir "sampled" mummies.
I see what you're saying. Do you see any connection to what Oshun has been pushing since the results of the Abusir Mummy paper? that 10fold leap population expansion in middle/lower Aegypt 2Kbp though.
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Elmaestro: Explain why Bayes law is bullshit or shouldn't be applied in the OP or stay in the cut. I wont chase you around while you reinvent the meaning of scientific concepts, you KNOW for a fact that Hg assignments are binary and that you have to have a mutation indicative of R1B1 to be R1b1a1a. and though the bin Nomenclature can change, the mutations stay the same (as well as the relationship between them) so half of your argument is already out of the window.... why mislead your people like that?
Break down Bayes theorem and how it is being misused in the OP, While you're at it, explain why Bayesian stats fail in ADMIXTURE as well as STRUCTURE, etc... It ain't that hard, put up or shut up.
What you wrote sounds stupid. You wrote " you KNOW for a fact that Hg assignments are binary and that you have to have a mutation indicative of R1B1 to be R1b1a1a. and though the bin Nomenclature can change, the mutations stay the same ", this was a stupid statement because the mutations determine the nomenclature of the clade a genome belongs, as a result the mutations for R1b1, are not the same as R1b1a1a the additional letters for the clade R1b1a1a denote additional mutations.
Yes Bayes statistics are bs when usedby geneticist. "In probability theory and statistics, Bayes theorem (alternatively Bayes law or Bayes' rule) describes the probability of an event, based on prior knowledge of conditions that might be related to the event." For example, if an individual's ancestry is determined by their ethnicity, using Bayes theorem, a persons ethnicity can be used to more accurately assess the probability that they carry a particular haplogroup, compared to the assessment of the probability of an individual's ancestry made without knowledge of the person's ethnicity.
Admixture and Structure programs assume that their are four pristine ethnic population or races: Sub-Saharan African, Western Eurasian (Sub-clade in Middle East), Eastern Eurasian and Native American. Because these races are considered pristine, each population is assigned a specific set of haplogroups, e.g., SSA population mtDNA belong to L haplogroups and Y-DNA is A and E. The problem with these assumptions is that SSA carry all the haplogroups associated with the Eurasians and Native Americans. Due to this, geneticist have to mask selected genes so they can get the results they want.
Bayes' theorem is stated mathematically as the following equation:[2]
Where A and B are the probabilities of observing A and B without regard to each other. P(A\B), a conditional probability is the probability of observing event A given that B is true. P(B\A) is the probability of observing event B given that A is true.
In other words if P(ethnicity\SNPs) is a conditional probability it the probability of observing that ethnicity (A) x SNPs (B) = an individuals haplogroup is true.
P(SNPs\ethnicity) is the probability of observing that given SNPs x ethnicity= an individuals haplogroup.
The equation fails in determining the admixture between SSAs and Eurasians, because Africans carry all the genes found among Eurasians.
As a result, using Bayesian statistics in admixture programs is bs because P(ethnicity \SNPs) does not predict the haplogroups carried by SSAs because we carry all the haploghroups.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
quote:Originally posted by the lioness,: yes, everything is white supremacy
Blah blah bah always back paddling and not responding to questions, always claiming obvious white supremacy is actually not that, always claiming everything is "Afrocentric lunacy".
So what are your degrees since you are on your high-horse?
Answer the questions I asked, don't back peddle. Be brave, I know you can do it.
Posts: 22234 | From: האם אינכם כילדי הכרית אלי בני ישראל | Registered: Nov 2010
| IP: Logged |
posted
"the additional letters for the clade R1b1a1a denote **ADDITIONAL** mutations." Congratulations,
"It's a lie to say over Half of the African continent has people who are E1b1/ Pn2.... because 99.999% of them are either E1b1a1a... E1b1a1b1.... E1b1a2a.... E1b1b2 etc." hahaha lmao straight trickoloy.
Congratulations x2 for figuring out/posting bayes theorem, however I don't understand wtf you're talking about past that... and probably neither do you.
quote: ""[...] In other words if P(ethnicity\SNPs) is a conditional probability it the probability of observing that ethnicity (A) x SNPs (B) = an individuals haplogroup is true.
P(SNPs\ethnicity) is the probability of observing that given SNPs x ethnicity= an individuals haplogroup.
The equation fails in determining the admixture between SSAs and Eurasians, because Africans carry all the genes found among Eurasians.
As a result, using Bayesian statistics in admixture programs is bs because P(ethnicity \SNPs) does not predict the haplogroups carried by SSAs because we carry all the haploghroups.""
Huh? ...I have so many questions, lol. like, what numerical value does Ethnicity have? lmao are you talking about online public calculators, and predictors...? I don't know of a contemporary peer reviewed study that'd use ethnicity to determine a Haplogroup. btw, do you not know that haplogroups are arbitrarily ASSIGNED? even if all genetic mutations come from Africans, a haplogroup would be designated to help organize/analyze population structure & to better understand who belongs where... What you say makes no sense at all, from any angle. & what does this have to do with the OP?
"Admixture and Structure programs assume that their are four pristine ethnic population or races: Sub-Saharan African, Western Eurasian (Sub-clade in Middle East), Eastern Eurasian and Native American." -Clyde Winters ...Yeah, how sway?
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Elmaestro: "It's a lie to say over Half of the African continent has people who are E1b1/ Pn2 . because 99.999% of them are either E1b1a1a E1b1a1b1.... E1b1a2a.... E1b1b2 etc."
This is interesting, because we are speaking of surviving populations in Africa. Populations that arose out of small pockets, that spread out had bottlenecks and drifts, or either died off. D/E is one of those examples.
quote:
Schematic of a serial found effect. We illustrate the effect of serial founder events on genetic diversity in the context of the OOA expansion. Colored dots indicate genetic diversity. Each new group outside of Africa represents a sampling of the genetic diversity present in its founder population. The ancestral population in Africa was sufficiently large to build up and retain substantial genetic diversity.
The third assumption is that there have been no dramatic postexpansion bottlenecks that differentially affected populations from which the serial migration began. If the source population for the expansion suffered a severe bottleneck that reduced its genetic diversity, we should see a poorer linear fit to the decline of heterozygosity with distance from Africa, or erroneously assign a population with higher genetic diversity as the source population. It is this third assumption we believe deserves additional consideration.
--Brenna M. Henna, L. L. Cavalli-Sforzaa and Marcus W. Feldmanb.
My new thread is on Ghost populations. It is specially dedicated to that.
quote:Originally posted by the lioness,: I have a degree in fly swatting
That is what I assumed and I am really not surprised to be honest. So where did you earn that degree? Don't back peddle. Be brave, I know you can do it.
Posts: 22234 | From: האם אינכם כילדי הכרית אלי בני ישראל | Registered: Nov 2010
| IP: Logged |
quote:Originally posted by Elmaestro: "the additional letters for the clade R1b1a1a denote **ADDITIONAL** mutations." Congratulations,
"It's a lie to say over Half of the African continent has people who are E1b1/ Pn2.... because 99.999% of them are either E1b1a1a... E1b1a1b1.... E1b1a2a.... E1b1b2 etc." hahaha lmao straight trickoloy.
Congratulations x2 for figuring out/posting bayes theorem, however I don't understand wtf you're talking about past that... and probably neither do you.
quote: ""[...] In other words if P(ethnicity\SNPs) is a conditional probability it the probability of observing that ethnicity (A) x SNPs (B) = an individuals haplogroup is true.
P(SNPs\ethnicity) is the probability of observing that given SNPs x ethnicity= an individuals haplogroup.
The equation fails in determining the admixture between SSAs and Eurasians, because Africans carry all the genes found among Eurasians.
As a result, using Bayesian statistics in admixture programs is bs because P(ethnicity \SNPs) does not predict the haplogroups carried by SSAs because we carry all the haploghroups.""
Huh? ...I have so many questions, lol. like, what numerical value does Ethnicity have? lmao are you talking about online public calculators, and predictors...? I don't know of a contemporary peer reviewed study that'd use ethnicity to determine a Haplogroup. btw, do you not know that haplogroups are arbitrarily ASSIGNED? even if all genetic mutations come from Africans, a haplogroup would be designated to help organize/analyze population structure & to better understand who belongs where... What you say makes no sense at all, from any angle. & what does this have to do with the OP?
"Admixture and Structure programs assume that their are four pristine ethnic population or races: Sub-Saharan African, Western Eurasian (Sub-clade in Middle East), Eastern Eurasian and Native American." -Clyde Winters ...Yeah, how sway?
LOL. Your statements make no sense. Admixture programs compare ethnic groups/ populations based on the SNPs of each individual within the ethnic group /population.
You claim to understand admixture programs; Yet you said
quote:"Huh? ...I have so many questions, lol. like, what numerical value does Ethnicity have? lmao"
Look at the figure below what are the criterions in each column? .
.
Oops. The Columns represent ethnic groups or populations.To make the columns you have to give the SNPs of each member of an ethnic group a numerical value.
After viewing the chart above you may understand why P(ethnicity\SNPs) is a conditional probability it the probability of observing that the ethnicity (of individuals) (A) x SNPs (B) = an individuals haplogroup or membership in a population is true.
P(SNPs\ethnicity) is the probability of observing that given SNPs x ethnicity= an individuals haplogroup/ancestral component as a member of a given population.
lmao. This figure shows how the ethnicity of the indiviuals in the study was given numerical value to make the columns in the above figure.This figure makes it clear you don't know what you're talking about, and my interpretation of Bayes law in relation to admixture programs is SWAY.
Your failure to understand admixture programs explains why you did not understand the use of Bayes law in relation to population genetics. It also explains why you accept what ever population genetics article you read as valid and reliable, when the study in reality may be invalid.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
Perfect for allowing the Wolf to pull the wool over your eyes.
There are literally billions or even trillions of transmutation permutations in gene altering and whites are just no where near intellect enough to track these convolutions in real-time. They really need to advance artificial (IBM Watson) intelligence to utilize machine learning to catalog the tens of trillions of test/evaluate/record iterations required to just decode mouse gnome even before they can think about humans.
Meanwhile, there's a sucker born every minute to accept and believe the limited filtered data they choose to release.
posted
@Clyde 1.You don't have to stretch the thread to make a point.
2. how does P(ethnicity/SNPs) determine haplogroups... stick to you're original point. Which numerical value is used for Ethnicity to determine the probability one's set of SNPs belongs to a Haplogroup, Clyde...
3. each color represents % membership based on K-means, ADMIXTURE uses algorithms to try to converge on the "best probable likelyhood" for ancestry given which ever amount of "Ancestors"(K) you specify or are looking for... every coloumn in the above example represents an Individual, the population or ethnic group they belong to isn't determined or specified by ADMIXTURE.
If you play around with the program, you will see that 1 individual can represent its own K or ancestral component and also that 1 individual can cluster poorly within his supposed Ethnic group. Variants aren't assigned to no god damned ethnic group, the supposed groups are inferred by the observer AFTER the run.
Next time you run ADMIXTURE specify a non default termination condition, then plot your results. You will see that the program uses probability to "assign K" to the pool of variants/ based on frequency (differences between individuals in the dataset). then relaxes on a likelyhood.
Like breux, plug in the numbers to your equation!!! How does what you say make any sense!!?
Do you know that populations or individuals who share Variants can belong to two completely different clusters, you beleive that the Wichi shares no SNPs with the Han for example, according to the program (or is given different "ethnic values")? Wtf Clyde?
And here's the final Ether, ADMIXTURE doesn't even use Bayesian statistics to calculate % membership to a particular "cluster"... the most is does with Bayes approach is use it to calculate cross validation AFTER the fact, for help deciding on which number of "K" best represents the sampleset.
So let's get back on Topic.... Explain how Bayes theorem in the OP should be used better or is inappropriate for use... I'm only responding to you out of whatever respect that I have for you... Put up ...or, ...you know the rest.
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Elmaestro: @Clyde 1.You don't have to stretch the thread to make a point.
2. how does P(ethnicity/SNPs) determine haplogroups... stick to you're original point. Which numerical value is used for Ethnicity to determine the probability one's set of SNPs belongs to a Haplogroup, Clyde...
3. each color represents % membership based on K-means, ADMIXTURE uses algorithms to try to converge on the "best probable likelyhood" for ancestry given which ever amount of "Ancestors"(K) you specify or are looking for... every coloumn in the above example represents an Individual, the population or ethnic group they belong to isn't determined or specified by ADMIXTURE.
If you play around with the program, you will see that 1 individual can represent its own K or ancestral component and also that 1 individual can cluster poorly within his supposed Ethnic group. Variants aren't assigned to no god damned ethnic group, the supposed groups are inferred by the observer AFTER the run.
Next time you run ADMIXTURE specify a non default termination condition, then plot your results. You will see that the program uses probability to "assign K" to the pool of variants/ based on frequency (differences between individuals in the dataset). then relaxes on a likelyhood.
Like breux, plug in the numbers to your equation!!! How does what you say make any sense!!?
Do you know that populations or individuals who share Variants can belong to two completely different clusters, you beleive that the Wichi shares no SNPs with the Han for example, according to the program (or is given different "ethnic values")? Wtf Clyde?
And here's the final Ether, ADMIXTURE doesn't even use Bayesian statistics to calculate % membership to a particular "cluster"... the most is does with Bayes approach is use it to calculate cross validation AFTER the fact, for help deciding on which number of "K" best represents the sampleset.
So let's get back on Topic.... Explain how Bayes theorem in the OP should be used better or is inappropriate for use... I'm only responding to you out of whatever respect that I have for you... Put up ...or, ...you know the rest.
Stop making stuff up.Researchers when they write genetics articles claim they are using Bayesian statistics.
1. I already explained above how Bayes theorem is inappropriate in studying African and Afro-American admixture in relation to other populations.
2) I explained that admixture programs give individual members of varied ethnic groups a numerical value to represent each individual in the population sample.
Yes Bayes statistics are bs when usedby geneticist. "In probability theory and statistics, Bayes theorem (alternatively Bayes law or Bayes' rule) describes the probability of an event, based on prior knowledge of conditions that might be related to the event." For example, if an individual's ancestry is determined by their ethnicity, using Bayes theorem, a persons ethnicity can be used to more accurately assess the probability that they carry a particular haplogroup, compared to the assessment of the probability of an individual's ancestry made without knowledge of the person's ethnicity.
Admixture and Structure programs assume that their are four pristine ethnic population or races: Sub-Saharan African, Western Eurasian (Sub-clade in Middle East), Eastern Eurasian and Native American. Because these races are considered pristine, each population is assigned a specific set of haplogroups, e.g., SSA population mtDNA belong to L haplogroups and Y-DNA is A and E. The problem with these assumptions is that SSA carry all the haplogroups associated with the Eurasians and Native Americans. Due to this, geneticist have to mask selected genes so they can get the results they want.
Bayes' theorem is stated mathematically as the following equation:[2]
Where A and B are the probabilities of observing A and B without regard to each other. P(A\B), a conditional probability is the probability of observing event A given that B is true. P(B\A) is the probability of observing event B given that A is true.
P(ethnicity\SNPs) is a conditional probability it the probability of observing that the ethnicity (of individuals) (A) x SNPs (B) = individuals P(ethnicity\SNPs) is a conditional probability it the probability of observing that the ethnicity (of individuals) (A) x SNPs (B) = an individuals haplogroup or membership in a population is true.
P(SNPs\ethnicity) is the probability of observing that given SNPs x ethnicity= an individuals ancestral component and membership in a given population is true.
P(SNPs\ethnicity) is the probability of observing that given SNPs x ethnicity= an individuals haplogroup/ancestral component as a member of a given population.
The equation fails in determining the admixture between SSAs and Eurasians, because Africans carry all the genes found among Eurasians.
As a result, using Bayesian statistics in admixture programs is bs because P(ethnicity \SNPs) does not acurately predict the ancestral components carried by SSAs because we carry ancestral components carried by Eurasians and Native Americans.
-------------------- C. A. Winters Posts: 13012 | From: Chicago | Registered: Jan 2006
| IP: Logged |
I don't have the dexterity to chase bunnies in circles, while holding in these progressive layers upon layers of disappointment smh... you're completely out of touch man.
Posts: 1781 | From: New York | Registered: Jul 2016
| IP: Logged |
quote:Originally posted by Elmaestro: I'm sorry...
I don't have the dexterity to chase bunnies in circles, while holding in these progressive layers upon layers of disappointment smh... you're completely out of touch man.
If we apply the "bayesian statistics", how many bunnies in circles would that be?
Posts: 22234 | From: האם אינכם כילדי הכרית אלי בני ישראל | Registered: Nov 2010
| IP: Logged |




 UBBFriend: Email this page to someone!
UBBFriend: Email this page to someone!












 Printer-friendly view of this topic
Printer-friendly view of this topic